Ein solides File Management ist der erste Schritt zu guter Datenqualität im Datawarehouse. Wie kann man File Management im Modern Datawarehouse realisieren? Ein Ansatz sind die Azure Datafactory und Azure Databricks. Azure Functions bieten hier eine gute Alternative. Bevor ich euch die Lösung zeige, will ich das Problem noch etwas eingrenzen.
File Management
Häufig müssen verschiedenste Arten von Dateien in ein Datawarehouse importiert werden.
CSV-Dateien sind bei großen Datenvolumen, im Vergleich zu HTTP-Schnittstellen, schnell exportiert und schnell importiert.
XLSX-Dateien sind üblich, wenn es eine Schnittstelle mit einem manuellen Prozess gibt und ein Anwender Daten in Excel bearbeitet.
XML-Dateien erlauben den Austausch von komplexen Datenstrukturen zwischen Systemen.
Ein bewährtes Vorgehen ist für Schnittstellen-Dateien Metadaten zu erfassen, etwa wann eine Datei registriert und geladen wurde. Gleichzeitig sollten diese Dateien archiviert werden. Manchmal müssen die Dateien noch konvertiert werden.
Das Modern Datawarehouse
Realisiert man klassische Datawarehouse-Architekturen in der Cloud führt kaum ein Weg an Infrastructure as a Service vorbei. Das größte Potenzial bietet die Cloud aber bei Platform as a Service, da im Leerlauf weniger Ressourcen verbraucht werden und damit Kosten sinken können.
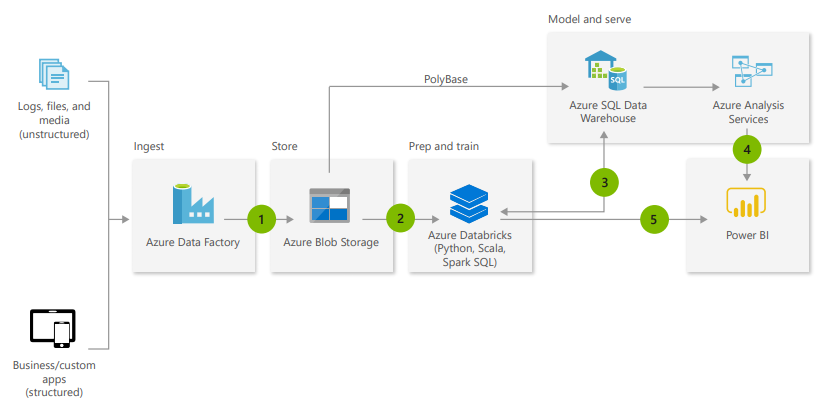
Eine Datawarehouse-Architektur die auf Platform as a Service realisiert werden kann ist das von Microsoft vorgeschlagene Modern Datawarehouse
Das sieht folgendermaßen aus:
Azure Functions
Azure Functions sind zustandslose Webservices, die auf unterschiedlichste Ereignisse registriert werden können und dann eine bestimmte Aufgabe erledigen sollen. Ereignisse können Zeitpläne, HTTP-Requests oder Änderungen in einem Azure Blob-Store sein. Kosten entstehen pro Aktivierung einer Funktion und skalieren so gut mit der entstandenen Last.

Problemstellung und Lösungsansatz
Die Datenhaltung im Modern Datawarehouse ist keine Relationale Datenbank sondern ein Data Lake. Ein Data Lake ist im Kern ein Dateisystem.
Die Datenintegration legt Dateien im Lake ab und Konsumenten lesen die Dateien. Dabei ist essentiell, dass die Daten geordnet abgelegt werden. Nach Möglichkeit müssen die Daten partitioniert werden, sodass bei Zugriffen nicht alle Dateien durchsucht werden müssen.
Welche Komponente übernimmt jetzt das File Management? Eigentlich müsste die Azure Data Factory diesen Aspekt abdecken. Ist aber noch recht limitiert und eignet sich eher für simples Data Movement. Alternativ kann das File Management in Databricks implementiert werden.
Azure Functions sind hier aber preislich günstiger und nicht weniger leistungsfähig.
Rechnet man mit wenigen hundert Dateien, die pro Tag verarbeitet werden wird man das Gratisvolumen von 1 Mio. Zugriffen kaum ausschöpfen.
Ein anderer Vorteil gegenüber der Azure Data Factory ist, dass man hier vollwertige Programmiersprachen wie C# oder Python verwenden kann. Mit Konzepten wie Vererbung kann ein großer Teil des Codes wiederverwendet werden und muss pro Datei-Typ nur sehr wenig Code zusätzlich geschrieben werden.
Design
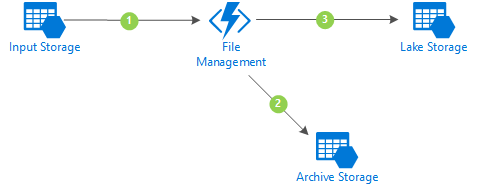
Das Design ist simpel. Es gibt drei Azure Storage Accounts. Einen für den Input, einen für das Archiv und einen für den Data Lake. Im Input und im Archive existiert jeweils für jeden Dateityp ein Blob Container. Im Lake Storage gibt es nur einen gemeinsamen Container.
Jetzt wird eine Datei im Input abgelegt. In meinem Beispiel ist das ein Microsoft Flow, der einen Anhang aus einer E-Mail mit einem speziellen Betreff ablegt. Das könnte aber genauso ein AzCopy-Aufruf von einem Dienstleister sein.
Eine Azure Function ist auf neue Dateien im Input Blob Container registriert und wird aktiviert (Punkt 1 in der folgenden Grafik).
Die Function erzeugt ein Verzeichnis im Archiv Container mit dem aktuellen Zeitstempel und kopiert die Datei unbearbeitet in das neue Verzeichnis. Damit können keine Dateien überschrieben werden oder verloren gehen (Schritt 2).
Im Lake Container gibt es jeweils je Dateityp ein Verzeichnis.
Die Function vergibt der Datei einen neuen eindeutigen Namen, konvertiert bei Bedarf den Zeichensatz und legt die Datei im Lake Storage ab.
Dazu werden noch die Metadaten als eigener Dateityp abgelegt, die bei Analysen verknüpft werden können (Schritt 3). Zuletzt wird noch die Datei aus dem Input gelöscht.
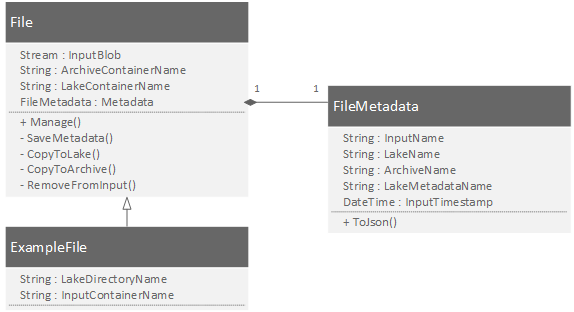
Die Struktur der Function ist in der folgenden Grafik gezeigt. Die gesamte Logik liegt in der File-Klasse und ist damit wiederverwendbar. In der spezifischen Klasse wird nur festgelegt in welchem Container der Input liegt und in welchem Verzeichnis die Daten im Lake abgelegt werden sollen. Die Metadaten werden als eigene einheitliche Klasse realisiert und können so leicht serialisiert und im Lake abgelegt werden.
Demo
Für die Demo habe ich eine DEV-Umgebung in Azure erzeugt. Zusätzlich zu den erklärten Services benötigen die Azure Functions noch einen weiteren Storage Account und einen App Service Plan. Dazu werden noch die Application Insights verwendet um die Lösung zu überwachen.
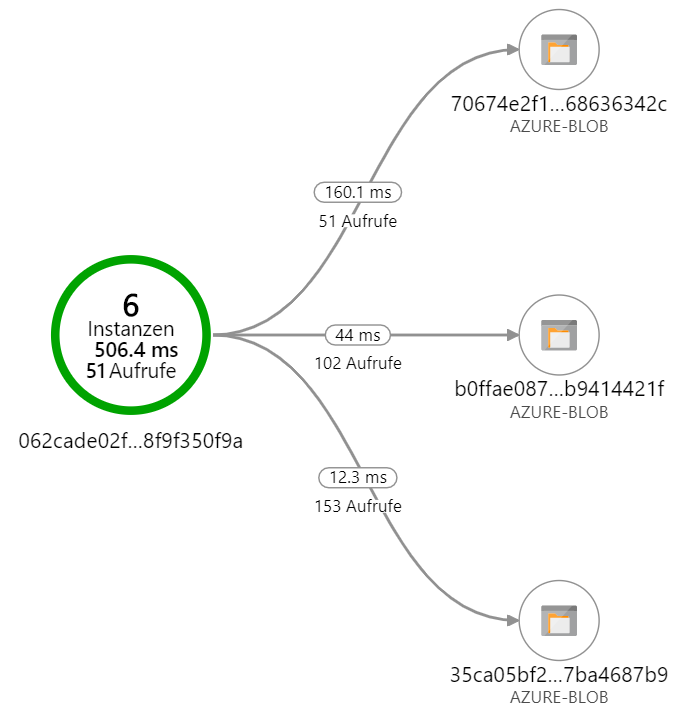
Die Application Insights zeigen auch, dass die Lösung tatsächlich läuft.
Im Storage Explorer kann man dann sehen, wie die Dateien im Lake abgelegt werden. Für jede Input-Datei wurde über eine GUID identifizierbar der Inhalt als CSV und die Metadaten als JSON abgelegt.