As data-driven and AI-first applications are on the advance, we extend our best practices for DevOps and agile development with new concepts and tools. The corresponding buzz words would be continuous intelligence and continuous delivery for machine learning (CD4ML).
For our current project, we researched, tried different approaches and build a proof of concept for a continuously improved machine learning model. That’s why I got interested in this topic and went to a meet up at Thoughtwork’s office. Christoph Windheuser (Global Head of Artificial Intelligence) shared their experience in this field and gave a lot of insights. The following post summarizes these thoughts [1] with some notes from our learning process.

The continuous intelligence cycle
1- Acquire data
Get your hands on data sets. There are multiple ways, most likely the data is bought, collected or generated.
2- Store, clean, curate, featurize information
Use statistical and explorative data analysis. Clean and connect your data. At the end, it needs to be consumable information.
3- Explore models and gain insights
You are going to create mathematical models. Explore them, try to understand them and gain insights in your domain. These models will forecast events, predict values and discover patterns.
4- Productionize your decision-making
Bring your models and machine learning services into production. Apply your insights and test your hypothesizes.
5- Derive real life actions and execute upon
Take actions on your gained knowledge. Follow up with your business and gain value. This generates new (feedback) data. With this data and knowledge, you follow up with step one of the intelligence cycle.
Productionizing machine learning is hard
There are multiple experts collaborating in this process circle. We have data hunters, data scientists, data engineers, software engineers, (Dev)Ops specialists, QA engineers, business domain experts, data analysts, software and enterprise architects… For software components, we mastered these challenges with CI/CD pipelines, iterative and incremental development approaches and tools like GIT and Docker (orchestrators). However, in continuous delivery for machine learning we need to overcome additional issues:
- When we have changing components in software development, we talk about source code and configuration. In machine learning and AI products, we have huge data sets and multiple types and permutations of parameters and hyperparameters. GitHub for example denies git pushes with files bigger than 100mb. Additionally, copying data sets around to build/training agents is more consuming than copying some .json or .yml files.
- A very long and distributed value chain may result in a "throw over the fence" attitude.
- Depending on your current and past history, you might need to think more about parallelism in building, testing and deploying. You might need to train different models (e.g. a random forest and an ANN) in parallel, wait for both to finish, compare their test results and only select the better performing.
- Like software components, models must be monitored and improved.
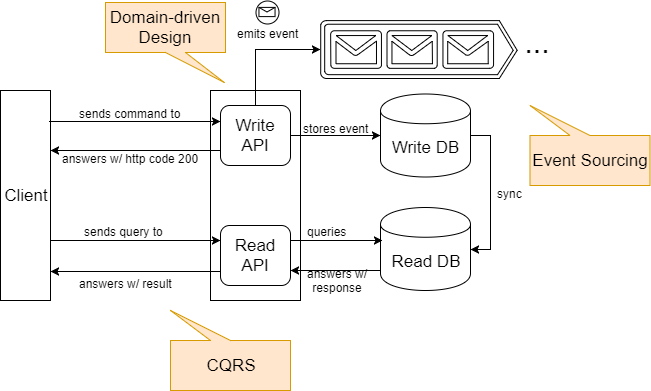
The software engineer’s approach
In software development, the answer to this are pipelines with build-steps and automated tests, deployments, continuous monitoring and feedback control. For CD4ML the cycle looks like this [1]:

There is a profusely growing demand on the market for tools to implement this process. While there are plenty of tools, here are examples of well-fitting tool chains.
| stack | discoverable and accessible data | version control artifact repositories | cd orchestration (to combine pipelines) |
|---|---|---|---|
| Microsoft Azure | Azure Blobstorage / Azure Data lake Storage (ADLS) | Azure DevOps Repos & ADLS | Azure DevOps Pipelines |
| open source with google cloud platform [1] | Google cloud storage | Git & DVC | GoCD |
| stack | infrastructure (for multiple environments and experiments) | model performance assessment | monitoring and observability |
|---|---|---|---|
| Microsoft Azure | Azure Kubernetes Service (AKS) | Azure machine learning services / ml flow | Azure Monitor / EPG * |
| open source with google cloud platform [1] | GCP / Docker | ml flow | EFK * |
* Aside from general infrastructure (cluster) and application monitoring, you want to:
- Keep track of experiments and hypothesises.
- Remember what algorithms and code version was used.
- Measure duration of experiments and learning speed of your models.
- Store parameters and hyperparameters.
The solutions used for this are the same as for other systems:
| search engine | log collector | visual layer | |
|---|---|---|---|
| EFK stack | elasticsearch | fluentd | kibana |
| EPG stack | elasticsearch | prometheus | grafana |
| ELK stack | elasticsearch | logstash | kibana |
[1]: C.Windheuser, Thoughtworks, Slideshare: https://www.slideshare.net/ChristophWindheuser/cd4ml-thoughtworks-meetup-munich-christoph-windheuser-may-8th-2019