
Die Entwicklung von Cloud-Anwendungen mit Azure PaaS bietet viele Vorteile für Unternehmen. Das Microsoft Data Center kümmert sich um die Verwaltung des Betriebssystems und des Application Servers. Für Unternehmen bedeutet das eine enorme Zeit- und Kostenersparnis.
Viele Unternehmen zögern jedoch aus Sicherheitsbedenken und Datenschutzgründen und bevorzugen den Betrieb im hauseigenen Rechenzentrum. Dabei ließe sich durch aktuelle Sicherheitstechnologien die Sicherheit von Public-Cloud-Anwendungen erheblich verbessern.
Dazu muss der Anwendungssicherheit in der System- und Anwendungsarchitektur jedoch genügend Raum gegeben werden. Wichtig ist es, die möglichen Bedrohungen zu analysieren und entsprechende Maßnahmen vorzusehen.
Während in der Vergangenheit häufig die Sicherung der Netzwerke im Vordergrund stand, rücken in der modernen Anwendungsarchitektur die Daten ins Zentrum der Bedrohungsanalyse. Unternehmen müssen sich über den Wert ihrer Daten klar werden, um die erforderlichen Schutzmaßnahmen zu treffen. Das ist die Aufgabe der Data Classification: Daten werden kategorisiert nach ihrer Vertraulichkeit und ihrem Business Impact, um sich über die Risiken und den erforderlichen Schutzmaßnahmen klarzuwerden.
Folgende Abbildung soll den groben Ablauf der Data Classification veranschaulichen:
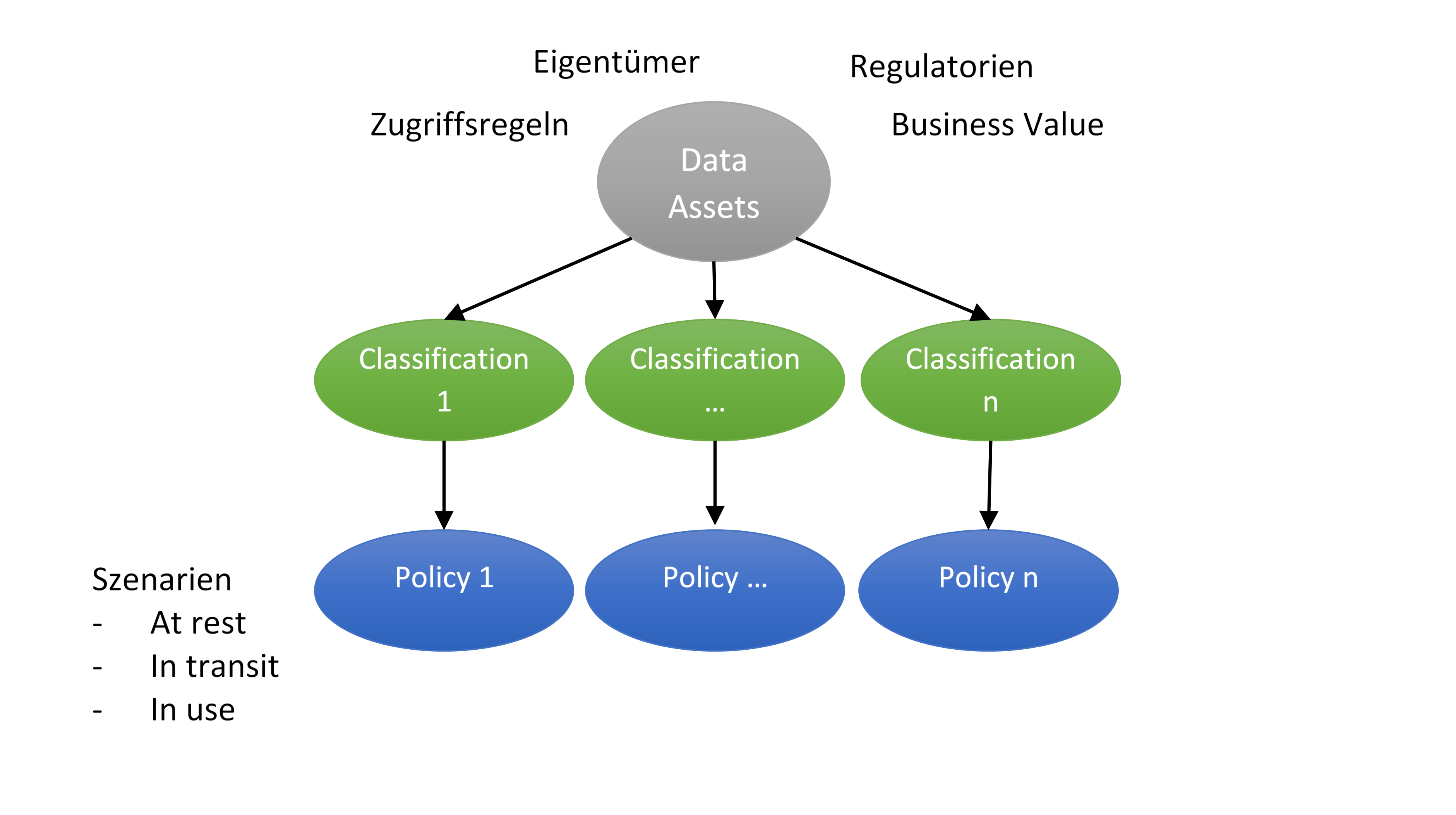
Die Daten (strukturierte wie unstrukturierte) werden zusammengefasst zu „Data Assets“. Bei diesem Vorgang müssen vor allem gesetzliche Regeln beachtet werden, wie zum Beispiel beim Umgang mit Gesundheits- oder Kreditkarteninformationen. Wichtig ist natürlich auch, ob Daten relevant für Geschäftsgeheimnisse sind und daher hohen Business Value besitzen. Daneben muss man berücksichtigen, wer Eigentümer der Daten ist und welche Zugriffsregeln gelten sollen.
Jedes Data Asset wird dann einer Classification zugeordnet. Solche Kategorien können so einfach gewählt sein wie Restricted, Sensitive und Unprotected. Oder ausgefeilter wie die Data Classification des National Institutes for Standards and Technology (NIST), das die Kategorien nach den klassischen Security Objectives (Confidentiality, Integrity, Availability) und dem Potential Impact (Low, Moderate, High) ausrichtet.
Jeder Classification wird dann eine Policy zugeordnet, die konkrete Schutzmaßnahmen definiert, wie zum Beispiel den Speicherort und ob und wie Daten verschlüsselt werden müssen. Die Cloud Security Alliance unterscheidet dabei zwischen folgenden Szenarien:
- Data at Rest: Das sind Daten, die in einem Speicher abgelegt sind, z. B. einer Datenbank
- Data in Transit: Daten, die zwischen Systemen ausgetauscht werden
- Data in Use: Daten, die gerade verarbeitet werden, z. B. für Berechnungen und die Anzeige in der Anwendung
Die Data Classification kann je nach Scope und selbstgesteckten Zielen ein beliebig komplexer Prozess sein. Hier gilt die Regel: Einfach ist besser als gar nicht, und gröber ist besser als zu detailversessen.
Manche Literatur empfiehlt aber, der Einfachheit halber die Klassifizierung auf Systemebene vorzunehmen. Gerade bei PaaS-Systemen dürfte es sich aber lohnen, eine Ebene tiefer zu gehen. So kann es sinnvoll sein, Teile eines Systems in der public Cloud zu betreiben, während die schutzbedürftigen Teile des Systems im eigenen Rechenzentrum betrieben werden.
Wenn man sich über das Schutzbedürfnis der Daten im Klaren ist, kann man leichter und ohne schlechtes Bauchgefühl bei den einzelnen Szenarien über die geeigneten Sicherheitsmaßnahmen entscheiden (oder kommt begründet zur Entscheidung, eine Anwendung nicht in die Public Cloud zu geben).
Die Sicherheitsmaßnahmen können dann von der geeigneten Authentifizierungsmethode über die Verschlüsselung der Datenbank und Netzwerkverbindungen bis hin zur Verschlüsselung einzelner Datenfelder gehen – die Technologien sind verfügbar. Wichtig ist nur, einen klaren Kopf zu behalten und analytisch vorzugehen.
Sicher, die Datenklassifizierung und die Sicherheitsmaßnahmen mögen aufwändig erscheinen. Aber Hand aufs Herz – eine stärkere Fokussierung auf die Daten und deren Sicherheit hätte auch bei mancher Intranet-Anwendung nicht geschadet. Schließlich kommt erfahrungsgemäß ein Großteil der Hacker-Angriffe aus dem eigenen Netzwerk.
Bei der Bedrohungsanalyse muss man sich übrigens nicht nur auf seine Erfahrung oder den Rat von Experten verlassen. Für einen ersten Überblick kann man auch auf automatisierte Tools zurückgreifen, wie z. B. Microsofts Threat Modeling Tool. Hier kann man Daten und Datenflüsse definieren und erhält einen Bericht über die möglichen Bedrohungen. Aber dazu ein andermal mehr.

Dein Kommentar
An Diskussion beteiligen?Hinterlasse uns Deinen Kommentar!