
Azure Cosmos DB
Working with Azure Cosmos DB usually is a pleasure. The initial setup process is fast and easy, working with documents very intuitive and once you go to production you don’t encounter any scaling barriers. It might not be the cheapest database out there, but you get what you pay for.
Challenge
Though we like working with Cosmos DB there are some pain points, you encounter along the road. The main issues we found would be a non-satisfying out-of-the-box backup mechanism and limitations to the API you choose. When you start with Azure Cosmos DB, you choose a query API. What you choose depends on the needs of your application. You can choose the graph API and query with gremlin, you can choose a mongo API, Cassandra API, use the Table API or fall back to a SQL-like API.
No DELETE in the SQL API
We use the SQL API. Coming from SQL databases this felt natural. However, there are two big restrictions:
- You can’t use most of SQL’s build in functions/keywords – but you can write your own userDefinedFunctions for whatever you want!
- You choose a query language. So only
SELECT ... from WHERE ...is allowed. NoDELETE!
This might sound strange, but you are not able to justDELETE * from c WHERE c._ts < unixTimeStamp. There are multiple ways of deleting documents, though. You can use any of the SDKs and write your own service, you can use stored procedures or delete documents manual – depending on your use case, which is fine most of the time.
Our use case was the following: "We <as development team> want to delete all data roughly before November 15th 2018". In other words, we want a simple bulk delete.
Solutions
We came up with multiple ideas how to do it:
- Write our own clean up (micro) service or enhance our existing persistency service. Good idea. We will do that in the future. However, we should have good tests in place when we want to ship a deleting service to production.
- [Use Cosmos DB stored procedures](https://github.com/Azure/azure-cosmos-dotnet-v2/blob/master/samples/clientside-transactions/DocDBClientBulk/DocDBClientBulk/bulkDelete.js "bulkDelete.js"). Good idea. You can write trivial or sophisticated JavaScript functions that are executed on "server" (Cosmos DB) side. The downsides here are restrictions for result length and the handling of continuation tokens.
- Use the time to live (TTL) feature of Cosmos DB.
The easy way
You can set a TTL for documents and/or containers (for SQL API: collections): The easiest way is to enable a TTL for documents, wait for the cosmos db to do the cleanup and then disable TTL again. Problem solved.
Our scenario: We have 67051 documents in one dev database. This is 1.72 GB of data and 142 MB for indexing. The newest document is from 27-Feb 2019, the oldest from 21-Jun 2018. We want to remove all data before 15-Nov 2018. So June, July, August, September, half of November. By default, every document in a collection contains a property _ts representing the unix time of the last change.
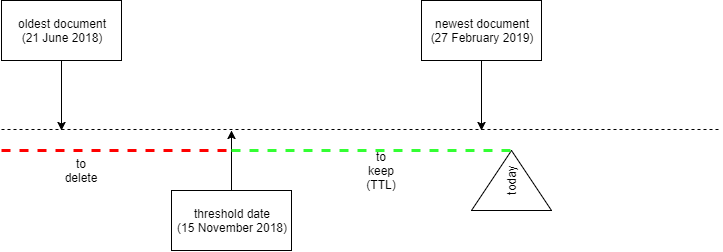
Documents we want to delete have a timestamp 1529566057 <= _ts < 1542240000 (1529566057 is 21 June 2018 07:27:37; 1542240000 is 15 November 2018 00:00:00).
The needed TTL to delete these documents is “unixTime.now()” - 1542240000 (15-Nov 2018 00:00:00). In our case 9042542 seconds. We use 9042542 as TTL in the database.
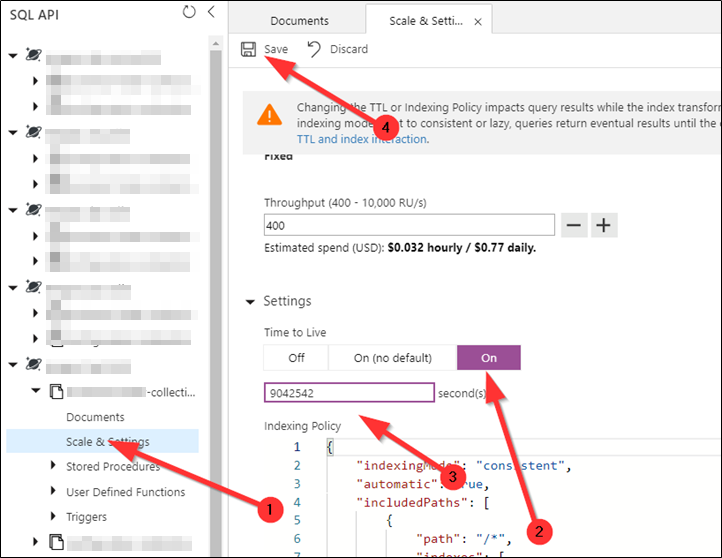
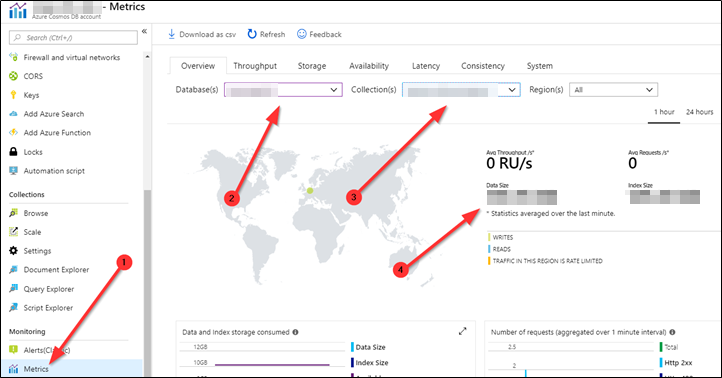
From now on all documents with a passed TTL are hidden and we cannot query for them anymore (SELECT (1) from c will not count them). However when we disable the TTL now again, the documents are visible again. We need to wait until cosmos db cleans the data up (can take some time). The cleanup will consume RU/s. We know the data is actually deleted when the data size in the metrics view shrinks.
Going forward…
There is a way to enable TTL for a collection, but not set a default ("TTL: on (no default)"). You can then set the TTL per document. So you can persist some of your documents permanently and dispose some (e.g. keep regression test data for two weeks, but delete automatically after to not generate data waste). Find more information on this topic at [the Microsoft documentation](https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-time-to-live#set-time-to-live-on-an-item "set time to live on an item").

Thank you for this article! Regarding what you say about “We need to wait until cosmos db cleans the data up” – how long does this take, in your experience? I have now waited 15 hours for my storage space to go down but it has yet to happen.
I think it depends on your defined throughput. A couple hundred documents should be deleted in roughly 10 min. 100k documents in about 4 hrs, I’d say. What’s your RU/s? I went with 10000 during cleanup.
Thank you for your reply! It’s been sitting on 3500 RUs and the metrics don’t show any high RU consumption over the past 15 hours. 130k documents, total around 700 MB in data size being deleted.